Find Duplicates in Microsoft Power Query: A Data Cleaning Essential
Find duplicates microsoft power query – Find duplicates in Microsoft Power Query is a fundamental skill for anyone working with data. It’s not just about tidying up your spreadsheets; it’s about ensuring data accuracy and reliability. Imagine you’re analyzing customer sales data, and you discover multiple entries for the same customer.
Without addressing duplicates, your analysis might be skewed, leading to inaccurate conclusions. This is where Power Query steps in, providing powerful tools to identify and handle duplicates, allowing you to confidently work with clean and reliable data.
Power Query offers a variety of methods for finding duplicates, from simple techniques like using the ‘Group By’ function to more advanced approaches involving custom functions and the ‘M’ language. We’ll explore these methods, providing practical examples and best practices to help you master duplicate detection in Power Query.
Introduction to Duplicate Detection in Power Query
Data cleaning is a crucial step in any data analysis process, and identifying and removing duplicate data is an essential part of this process. Power Query, a data transformation tool within Microsoft Excel and Power BI, offers powerful features for detecting and handling duplicates.Duplicate data can occur due to various reasons, such as data entry errors, merging multiple data sources, or data being copied and pasted incorrectly.
It can significantly impact data analysis by skewing results, creating misleading insights, and leading to incorrect decisions.
Finding duplicates in Microsoft Power Query is a common task, especially when dealing with large datasets. It’s amazing how technology has revolutionized data analysis, allowing us to quickly identify and remove duplicates with just a few clicks. The article technology has eaten the world perfectly captures this sentiment.
Power Query’s ability to handle duplicates is a testament to the power of technology to streamline our work and make us more efficient.
Importance of Duplicate Detection
Identifying and removing duplicate data is crucial for ensuring data quality and integrity. It allows you to:
- Gain accurate insights: Duplicate data can inflate counts and averages, leading to inaccurate analysis and potentially misleading conclusions. Removing duplicates ensures that your analysis is based on unique data points, providing reliable insights.
- Improve data efficiency: Duplicate data increases storage space requirements and can slow down data processing. Removing duplicates reduces the size of your dataset, improving efficiency and performance.
- Enhance data consistency: Duplicate data can introduce inconsistencies and conflicts within your data. Removing duplicates ensures data consistency and improves the overall quality of your data.
Real-World Examples of Duplicate Detection
Duplicate detection is essential in various real-world scenarios, including:
- Customer Relationship Management (CRM): Duplicate customer records can lead to incorrect targeting, marketing campaigns, and customer service interactions. Removing duplicates ensures that each customer is represented only once, providing a clear and accurate view of your customer base.
- Financial Reporting: Duplicate transactions can result in inaccurate financial statements and reporting. Removing duplicates ensures that all transactions are accounted for correctly, leading to reliable financial reporting.
- Scientific Research: Duplicate data points in scientific experiments can skew results and affect the validity of research findings. Removing duplicates ensures that the data accurately reflects the experiment’s results, enhancing the reliability and credibility of the research.
Consequences of Not Addressing Duplicate Data
Failing to address duplicate data can have several negative consequences:
- Inaccurate Analysis and Insights: Duplicate data can lead to skewed results, inflated counts, and incorrect averages, resulting in misleading insights and potentially flawed conclusions.
- Misinformed Decisions: Decisions based on inaccurate data can lead to costly mistakes and missed opportunities. Removing duplicates ensures that decisions are based on reliable information.
- Data Integrity Issues: Duplicate data can introduce inconsistencies and conflicts within your dataset, affecting data integrity and overall quality.
- Performance Degradation: Duplicate data increases storage space requirements and can slow down data processing, impacting overall performance and efficiency.
Identifying Duplicates Based on Specific Columns
In many scenarios, you might only need to identify duplicates based on specific columns within your data. This is where the power of Power Query’s ‘Group By’ function shines. This function allows you to group rows based on the values in selected columns, effectively highlighting duplicates within those specific columns.
Defining Columns for Duplicate Detection
You can control which columns are considered when identifying duplicates by specifying the columns in the ‘Group By’ function. This enables you to focus on the most relevant data for duplicate analysis. For example, you might want to identify duplicate customer records based on their ‘Customer Name’ and ‘Email’ columns.
Finding duplicates in Microsoft Power Query is a valuable skill for any data analyst, especially when you’re dealing with large datasets. It’s crucial to identify and remove duplicate entries to ensure data integrity and prevent skewed results. With the recent rise in automotive fraud, as reported by Equifax Canada, equifax canada reports rise in automotive fraud , it’s even more important to have clean data for accurate fraud detection and prevention.
By mastering Power Query’s duplicate detection tools, you can help ensure the reliability of your data and make informed decisions.
This means that even if a customer has different phone numbers or addresses, they will be considered a duplicate if their name and email address are the same.
Using the ‘Group By’ Function with Multiple Columns
The ‘Group By’ function allows you to specify multiple columns for grouping. This is essential for accurately identifying duplicates based on a combination of criteria.
The syntax for the ‘Group By’ function is:Table.Group(Table, “Column1”, “Column2”, …, “AggregationFunction1”, “AggregationFunction2”, …)
Here’s how it works:
1. Table
The table containing the data you want to analyze.
- “Column1”, “Column2”, …: The list of columns you want to group by.
- “AggregationFunction1”, “AggregationFunction2”, …: The list of aggregation functions you want to apply to the grouped data. For duplicate detection, you can use functions like ‘Count’ or ‘CountRows’ to identify the number of occurrences of each unique combination of values.
Examples of Duplicate Detection for Specific Columns
* Customer Data:Identify duplicate customer records based on ‘Customer Name’ and ‘Email’ to ensure data accuracy and avoid sending duplicate marketing emails.
Product Catalog
Identify duplicate product entries based on ‘Product Name’ and ‘SKU’ to ensure consistent product information and avoid inventory discrepancies.
Finding duplicates in Microsoft Power Query is a crucial step in data cleaning, ensuring data accuracy and preventing errors in your analysis. This process can be streamlined using various methods within Power Query, and it’s often a valuable skill to have, especially when dealing with large datasets.
For example, a recent news article hampton financial corporation announces the appointment of new ceo of its oxygen working capital subsidiary may have reported on a company’s financial data, which would benefit from data cleaning to ensure accuracy and reliability.
Understanding how to identify and handle duplicates in Power Query can help you analyze and interpret data more effectively, leading to more insightful conclusions.
Sales Orders
Identify duplicate sales orders based on ‘Order Number’ and ‘Customer ID’ to prevent accidental double-billing.
Handling Duplicates in Power Query
Power Query offers powerful tools for handling duplicate data, allowing you to refine your data by removing, merging, or flagging duplicates. This flexibility empowers you to ensure data accuracy and consistency, leading to more meaningful insights.
Removing Duplicates
Removing duplicate rows is a common practice when you want to eliminate redundant information. Power Query provides a straightforward approach for this.
- Using the ‘Remove Duplicates’ Feature:Power Query’s ‘Remove Duplicates’ feature simplifies the process of eliminating duplicate rows. This feature allows you to select the columns you want to consider when identifying duplicates. For example, if you want to remove duplicates based on ‘CustomerID’ and ‘OrderDate,’ you can select these columns.
This ensures that rows with identical values in these columns are treated as duplicates.
- Filtering for Unique Values:Alternatively, you can filter your data to retain only unique values. This approach involves using the ‘Filter Rows’ feature and selecting the condition ‘Is Unique.’ This method allows you to keep rows with distinct values in the selected column(s), effectively eliminating duplicates.
Merging Duplicates
Merging duplicate data is a valuable technique when you need to combine information from multiple rows into a single row. Power Query’s ‘Group By’ function facilitates this process.
- Aggregating Data:The ‘Group By’ function allows you to group rows based on selected columns and apply aggregation functions to combine data. For instance, you can group rows by ‘CustomerID’ and then use the ‘Sum’ function to aggregate the ‘OrderAmount’ column, combining the order amounts for each customer into a single row.
- Combining Values:The ‘Group By’ function also allows you to combine values from different rows. For example, you can group rows by ‘CustomerID’ and then use the ‘Combine Values’ function to concatenate the ‘OrderDate’ column, combining the order dates for each customer into a single cell.
Flagging Duplicates, Find duplicates microsoft power query
Flagging duplicates can be useful for identifying and analyzing duplicate data without removing or merging it. Power Query provides features to add columns that indicate the duplicate status of each row.
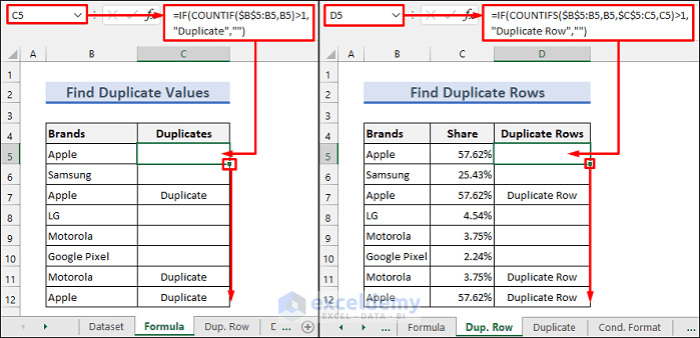
- Adding a ‘Duplicate’ Column:Power Query allows you to add a new column that flags duplicate rows. This column can be populated with a ‘True’ value for duplicate rows and ‘False’ for unique rows. This flag provides a visual indicator of duplicate rows within your data.
- Using Conditional Statements:You can use conditional statements to add a ‘Duplicate’ column based on specific criteria. For instance, you can create a conditional statement that assigns a ‘True’ value to the ‘Duplicate’ column if the values in the ‘CustomerID’ and ‘OrderDate’ columns match in multiple rows.
This allows you to flag duplicates based on your specific requirements.
Conditional Statements
Conditional statements play a crucial role in handling duplicates in Power Query. They allow you to perform actions based on the duplicate status of each row.
The ‘if’ statement in Power Query enables you to create conditional logic. You can use the ‘if’ statement to determine whether a row is a duplicate and then perform actions based on this determination.
- Removing Duplicates Based on Conditions:You can use conditional statements to remove duplicates only if they meet specific criteria. For example, you can remove duplicates only if the ‘OrderAmount’ is greater than a certain threshold. This selective approach ensures that you remove only relevant duplicates while preserving the rest of your data.
- Merging Duplicates Based on Conditions:Conditional statements can also be used to merge duplicates based on specific criteria. For example, you can merge duplicates only if the ‘CustomerID’ matches and the ‘OrderDate’ is within a certain time range. This allows you to combine relevant duplicates while preserving the integrity of your data.
Examples
Here are examples of how to use Power Query to handle duplicates:
- Removing Duplicates Based on CustomerID:To remove duplicate rows based on ‘CustomerID,’ you can use the ‘Remove Duplicates’ feature and select the ‘CustomerID’ column. This will eliminate rows with identical values in the ‘CustomerID’ column.
- Merging Duplicates Based on ProductID:To merge duplicate rows based on ‘ProductID’ and sum the ‘Quantity’ column, you can use the ‘Group By’ function, grouping by ‘ProductID’ and applying the ‘Sum’ function to the ‘Quantity’ column.
- Flagging Duplicates Based on OrderDate:To flag duplicate rows based on ‘OrderDate,’ you can add a new column named ‘Duplicate’ and use a conditional statement to assign a ‘True’ value to the ‘Duplicate’ column if the ‘OrderDate’ value is repeated in multiple rows.
Advanced Techniques for Duplicate Detection: Find Duplicates Microsoft Power Query
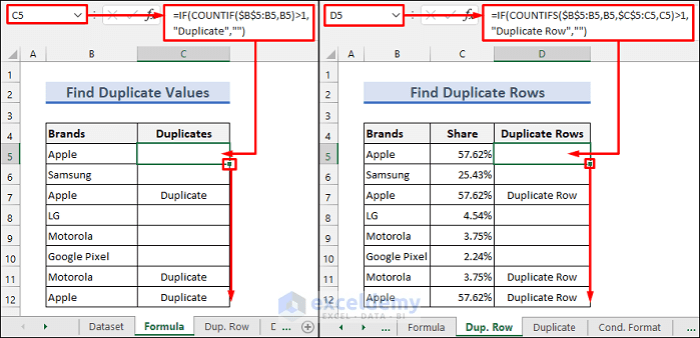
So far, we’ve explored basic methods for finding duplicates in Power Query. But what if your data requires more sophisticated analysis? This is where custom functions and Power Query’s ‘M’ language come into play. Let’s delve into these advanced techniques.
Custom Functions for Complex Duplicate Detection
Custom functions provide a powerful way to define your own logic for identifying duplicates. This is particularly useful when dealing with complex scenarios involving multiple columns or specific criteria.
- Defining a Custom Function:The ‘M’ language lets you create custom functions that encapsulate your duplicate detection logic. These functions can take input parameters (e.g., a table, column names) and return a table with duplicate rows flagged or removed.
- Example:Let’s say you want to identify duplicates based on a combination of “Customer ID” and “Order Date,” ignoring any differences in the “Order Amount” column. You could create a custom function like this:
let Source = Table.FromRows( "A", "2023-01-01", 100, "B", "2023-01-02", 150, "A", "2023-01-01", 120, // Duplicate based on "Customer ID" and "Order Date" "C", "2023-01-03", 200, "B", "2023-01-02", 150 // Duplicate based on "Customer ID" and "Order Date" , "Customer ID", "Order Date", "Order Amount"), DuplicateRows = Table.Group(Source, "Customer ID", "Order Date", "Count", each Table.RowCount(_), type number) in DuplicateRowsThis function groups rows based on “Customer ID” and “Order Date,” then counts the occurrences within each group. Rows with a count greater than 1 are considered duplicates.
Leveraging Power Query’s ‘M’ Language
Power Query’s ‘M’ language provides a flexible framework for manipulating data and defining advanced logic. You can use ‘M’ to:
- Filter Data Based on Specific Criteria:You can create custom filters that go beyond simple comparisons. For instance, you can filter rows based on conditions involving multiple columns, calculated values, or complex expressions.
- Transform Data for Duplicate Detection:You can use ‘M’ to transform your data into a format that makes duplicate detection easier. This might involve merging columns, splitting strings, or applying custom calculations.
Examples of Using Custom Functions for Specific Criteria
Let’s explore some scenarios where custom functions can be used to identify duplicates based on specific criteria:
- Ignoring Case Sensitivity:If you need to identify duplicates across columns that have different capitalization, you can use a custom function to convert the data to lowercase before comparing it.
- Matching Partial Strings:You might need to find duplicates based on partial matches within a string column. For example, identifying rows where a “Product Name” column contains the same substring. You can use ‘M’ functions like `Text.Contains` or `Text.Start` to implement this logic.
- Identifying Duplicates with a Tolerance:In some cases, you might want to consider values as duplicates if they fall within a certain tolerance range. For instance, if you have a column with prices, you might define a 5% tolerance for identifying duplicates. A custom function could use the `Number.Abs` function to calculate the absolute difference between values and compare it to your tolerance threshold.
Best Practices for Duplicate Detection in Power Query
Mastering duplicate detection in Power Query requires not just technical proficiency but also a strategic approach. This involves understanding the intricacies of your data, establishing clear processes, and implementing robust testing methodologies. By following these best practices, you can ensure the accuracy and reliability of your duplicate detection workflows, ultimately leading to cleaner and more valuable datasets.
Documentation and Data Understanding
Comprehensive documentation is essential for effective duplicate detection. This includes clearly outlining the data structure, identifying key columns involved in duplicate identification, and defining the criteria for duplicate detection. A well-structured data dictionary, outlining the purpose and meaning of each column, can significantly enhance the clarity and efficiency of your duplicate detection process.
Testing and Validation
Testing and validating your duplicate detection results are crucial to ensure accuracy. This involves comparing the results of your Power Query transformations with the original dataset or other reliable sources. Implementing manual checks, especially for smaller datasets, can help identify any discrepancies or potential errors.
Regularly testing your workflows with different datasets can also help identify potential issues and improve the robustness of your duplicate detection process.
Efficient Workflows
Efficient duplicate detection workflows are essential for handling large datasets. This involves optimizing your Power Query queries, minimizing unnecessary steps, and leveraging built-in functions like “Remove Duplicates” effectively. By understanding the performance implications of different approaches, you can streamline your workflows and ensure efficient duplicate detection, even for complex datasets.