

Data Ingestion vs ETL: A Data Pipeline Showdown
Data ingestion vs ETL sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail and brimming with originality from the outset.
In the realm of data processing, the terms “data ingestion” and “ETL” are often thrown around, but what exactly do they mean? And how do they differ? In this blog post, we’ll delve into the heart of these two essential processes, uncovering their distinct roles in the data pipeline.
We’ll explore the key differences between data ingestion and ETL, analyze their strengths and weaknesses, and ultimately determine which approach is best suited for your specific needs.
Data Ingestion: Data Ingestion Vs Etl
Data ingestion is the process of capturing data from various sources and preparing it for processing and analysis. It’s the foundational step in any data processing pipeline, laying the groundwork for everything that follows.
Data ingestion and ETL (Extract, Transform, Load) are crucial steps in data pipelines, and understanding their differences is key to building efficient and effective systems. While data ingestion focuses on bringing raw data into your system, ETL processes transform and cleanse data before loading it into target databases or data warehouses.
For scripting and automating these processes, PowerShell can be a powerful tool, especially if you’re looking for a comprehensive guide. Check out powershell the smart persons guide for a deep dive into its capabilities, which can help you streamline your data ingestion and ETL workflows.
Data Sources
Data ingestion involves collecting data from diverse sources, each with its own unique characteristics and formats.
- Databases: Traditional relational databases like MySQL, PostgreSQL, and Oracle store structured data in tables with well-defined columns and rows. Ingesting data from these sources often involves querying and extracting data based on specific criteria.
- APIs: Application Programming Interfaces (APIs) provide programmatic access to data from web services and applications. Ingesting data from APIs typically involves making requests and retrieving data in formats like JSON or XML.
- Files: Data can be stored in various file formats, such as CSV, JSON, XML, or text files. Ingesting file data involves reading and parsing the files, extracting the relevant information, and transforming it into a suitable format for further processing.
Data ingestion and ETL are critical for any organization that wants to leverage the power of data. While data ingestion focuses on getting data into your system, ETL goes a step further, transforming and loading it into a format suitable for analysis.
The UK government’s CMA is currently probing Amazon’s acquisition of Anthropic, raising concerns about potential antitrust issues. This highlights the importance of understanding data flows and ensuring fair competition in the tech sector, which in turn affects how companies like Amazon approach data ingestion and ETL processes.
- Streams: Streaming data sources like Kafka, Kinesis, or Apache Flume provide continuous streams of data in real-time. Ingesting streaming data involves processing the data as it arrives, typically using a streaming engine or framework.
Data Ingestion Methods
The choice of data ingestion method depends on several factors, including data volume, data format, and real-time requirements.
- Batch Ingestion: This method collects and processes data in batches at regular intervals. It’s suitable for large volumes of data that don’t require immediate processing, like periodic reports or historical data analysis. Batch ingestion is typically more efficient for handling large datasets.
- Streaming Ingestion: This method processes data as it arrives, often in real-time. It’s ideal for applications requiring low latency and immediate insights, such as fraud detection or online monitoring. Streaming ingestion is more complex but allows for near real-time data analysis.
Data Ingestion Tools
A wide range of tools are available to facilitate data ingestion, each with its strengths and weaknesses.
| Tool | Features | Strengths | Weaknesses |
|---|---|---|---|
| Apache Kafka | Distributed streaming platform for real-time data ingestion | High throughput, fault tolerance, scalability | Complex to manage, requires expertise |
| Amazon Kinesis | Fully managed streaming service for real-time data ingestion | Scalable, serverless, easy to use | Costly for large volumes, limited customization |
| Apache Spark | Open-source distributed computing framework for batch and streaming data processing | Fast and efficient, supports various data formats | Complex to configure and manage |
| Fivetran | Cloud-based data integration platform for automated data ingestion | Easy to use, pre-built connectors, managed service | Limited customization, can be expensive |
ETL

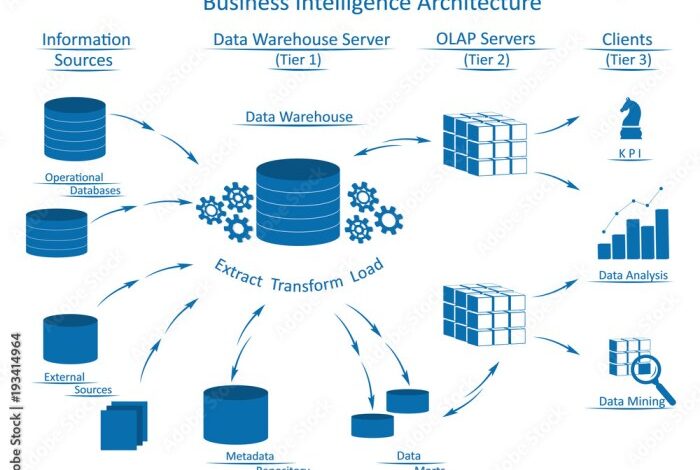
ETL (Extract, Transform, Load) is a data integration process used to move data from multiple sources into a single, consistent data store for analysis and reporting. It involves extracting data from various sources, transforming it into a usable format, and loading it into a target data warehouse or data lake.
ETL plays a crucial role in data warehousing, business intelligence, and data analytics, enabling organizations to gain insights from their data and make informed decisions.
Data ingestion and ETL (Extract, Transform, Load) are crucial for businesses, especially those with multiple locations or subsidiaries. You need a robust system to handle the influx of data from various sources, which is where a good accounting software like the ones discussed in this article on accounting software for multiple businesses can be invaluable.
These software solutions often come with built-in data ingestion and ETL capabilities, simplifying the process of getting your data ready for analysis and reporting.
Phases of ETL
The ETL process consists of three main phases:
- Extract:This phase involves extracting data from various sources, such as databases, flat files, APIs, or cloud services. The extraction process must be efficient and reliable, ensuring that all relevant data is captured without errors.
- Transform:In this phase, the extracted data is cleaned, standardized, and transformed into a format suitable for loading into the target data store. This involves tasks such as data cleansing, data aggregation, data enrichment, and data validation.
- Load:The final phase involves loading the transformed data into the target data store. This can be a data warehouse, data lake, or any other system that will be used for analysis. The loading process must be efficient and ensure data integrity.
Common Data Transformations
The transformation phase of ETL involves several common data transformations, including:
- Data Cleaning:This involves removing inconsistencies, errors, and duplicates from the data. It includes tasks like removing null values, handling missing data, and correcting data inconsistencies.
- Data Aggregation:This involves combining data from multiple sources or tables into a single table. This can be used to summarize data, calculate aggregates, and create new data points.
- Data Enrichment:This involves adding new data points to the existing data set. This can be done by joining data from different sources, using external data sources, or using data mining techniques.
- Data Validation:This involves ensuring that the data meets certain quality standards. This can include checking for data type errors, range errors, and other inconsistencies.
Benefits of Using ETL Tools
ETL tools provide several benefits for data transformation, including:
- Efficiency:ETL tools automate the data transformation process, reducing manual effort and increasing efficiency. They provide pre-built components and templates that simplify common data transformations.
- Scalability:ETL tools can handle large volumes of data and complex transformations. They can be scaled to meet the growing data needs of organizations.
- Data Quality:ETL tools provide features for data validation and cleansing, ensuring data quality and consistency. They help identify and correct data errors, reducing the risk of inaccurate analysis.
- Data Security:ETL tools offer security features to protect sensitive data during the transformation process. They provide access control, encryption, and auditing capabilities.
Hypothetical ETL Pipeline
Consider a scenario where a retail company wants to analyze customer purchase data from multiple sources, including online store transactions, loyalty program data, and social media interactions. An ETL pipeline can be designed to extract, transform, and load this data into a data warehouse for analysis.
- Extract:Data is extracted from the online store database, loyalty program database, and social media APIs.
- Transform:The extracted data is cleaned, standardized, and transformed into a consistent format. This involves tasks such as:
- Removing duplicates and null values.
- Standardizing customer names, addresses, and other data fields.
- Aggregating purchase data by customer and product.
- Enriching customer data with social media insights.
- Load:The transformed data is loaded into a data warehouse, where it can be used for analysis and reporting.
Data Ingestion vs. ETL
Data ingestion and ETL (Extract, Transform, Load) are two essential processes in data warehousing and analytics. While both aim to move data from source systems to a target data warehouse, they differ in their approach, scope, and purpose. Understanding these differences is crucial for choosing the right approach for your specific data needs.
Comparing Data Ingestion and ETL
Data ingestion and ETL are distinct processes with overlapping functionalities. While ETL focuses on extracting, transforming, and loading data, data ingestion primarily focuses on capturing and storing data.
- Data Ingestion:This process focuses on capturing and storing data from various sources, often in its raw format. It emphasizes speed and efficiency, aiming to get data into the target system quickly.
- ETL:This process involves extracting data from source systems, transforming it to meet the requirements of the target system, and then loading it into the target data warehouse. ETL emphasizes data quality, consistency, and compliance with business rules.
Scenarios for Data Ingestion and ETL, Data ingestion vs etl
The choice between data ingestion and ETL depends on the specific data requirements and use cases.
- Data Ingestion is preferred:
- When speed and efficiency are paramount, such as in real-time analytics or streaming data processing.
- When dealing with large volumes of data where transformation is not critical.
- When the data source is reliable and data quality is not a major concern.
- ETL is preferred:
- When data quality and consistency are crucial, such as in financial reporting or regulatory compliance.
- When data needs significant transformation to be usable in the target system.
- When dealing with complex data sources or multiple data sources that require harmonization.
Advantages and Disadvantages
The following table summarizes the advantages and disadvantages of data ingestion and ETL:
| Feature | Data Ingestion | ETL |
|---|---|---|
| Speed and Efficiency | High | Moderate to Low |
| Data Quality | Moderate | High |
| Scalability | High | Moderate |
| Complexity | Low | High |
| Cost | Low | High |
Impact on Data Quality, Performance, and Cost
The choice between data ingestion and ETL can significantly impact data quality, performance, and cost.
- Data Quality:ETL generally results in higher data quality due to data cleansing, transformation, and validation processes. Data ingestion, on the other hand, may result in lower data quality if data is not validated or cleansed before loading.
- Performance:Data ingestion is typically faster and more efficient than ETL, especially for large volumes of data. However, ETL processes can improve performance by optimizing data structures and eliminating redundant data.
- Cost:Data ingestion can be less expensive than ETL, as it involves fewer steps and resources. However, the cost of ETL can be justified if data quality and consistency are critical requirements.
Best Practices for Data Ingestion and ETL
Data ingestion and ETL (Extract, Transform, Load) processes are essential for making raw data usable and valuable. These processes can be complex, but by following best practices, you can ensure data quality, optimize performance, and make your data pipelines more efficient and reliable.
Ensuring Data Quality
Data quality is crucial for accurate insights and informed decision-making. To ensure high data quality during ingestion and ETL, consider the following practices:
- Data Validation:Implement comprehensive validation checks at every stage of the pipeline to catch errors and inconsistencies. This includes data type validation, range checks, and uniqueness checks.
- Data Cleansing:Cleanse data by removing duplicates, handling missing values, and correcting inconsistent formats. Use data cleansing tools and techniques to automate this process.
- Data Transformation:Apply transformations to ensure data consistency and compatibility with downstream systems. This includes data aggregation, normalization, and data enrichment.
- Data Profiling:Conduct regular data profiling to identify patterns, anomalies, and potential data quality issues. This helps to proactively address data quality problems before they impact downstream processes.
Optimizing Performance and Scalability
Performance and scalability are essential for handling large volumes of data efficiently. To optimize your data ingestion and ETL pipelines, consider the following strategies:
- Parallel Processing:Leverage parallel processing techniques to distribute data processing tasks across multiple processors or nodes, reducing overall processing time.
- Data Partitioning:Partition large datasets into smaller, manageable chunks to improve processing efficiency and reduce resource contention.
- Caching and Indexing:Utilize caching and indexing techniques to optimize data retrieval and reduce query execution times.
- Stream Processing:Implement stream processing techniques to process data in real-time, allowing for immediate insights and faster response times.
Choosing the Right Tools and Technologies
Selecting the right tools and technologies is crucial for building efficient and effective data ingestion and ETL pipelines. Consider the following factors when making your choices:
- Data Volume and Velocity:Choose tools that can handle the volume and velocity of your data. For high-volume, real-time data, consider stream processing platforms.
- Data Complexity and Structure:Select tools that support the complexity and structure of your data. For structured data, consider relational databases and data warehousing tools. For unstructured data, consider NoSQL databases and data lakes.
- Integration Requirements:Choose tools that integrate seamlessly with your existing systems and applications. Consider cloud-based platforms for scalability and ease of integration.
- Budget and Resources:Evaluate the cost of tools and the resources required to implement and maintain them. Consider open-source tools for cost-effective solutions.
Data Governance and Security
Data governance and security are paramount for protecting sensitive data and ensuring compliance with regulations. Consider the following practices:
- Data Access Control:Implement robust access control mechanisms to restrict access to sensitive data based on user roles and permissions.
- Data Encryption:Encrypt data at rest and in transit to protect it from unauthorized access.
- Data Lineage Tracking:Track the origin and transformations of data throughout the pipeline to ensure data provenance and accountability.
- Data Auditing and Monitoring:Implement auditing and monitoring mechanisms to track data access patterns, detect anomalies, and ensure compliance with security policies.