The evolution of Large Language Models (LLMs) from experimental conversational interfaces to core components of enterprise software architecture has necessitated a shift from raw text generation to precise, machine-readable interactions. In the early stages of LLM development, developers relied heavily on "prompt engineering"—the practice of explicitly instructing a model to "return only JSON" or "follow this specific schema." However, this approach was notoriously brittle, often resulting in "hallucinated" syntax errors, missing brackets, or unexpected conversational filler that broke downstream data pipelines. To resolve these inconsistencies, leading AI providers including OpenAI, Anthropic, and Google have introduced two distinct but often confused mechanisms: Structured Outputs and Function Calling. While both features aim to bridge the gap between stochastic language generation and deterministic software logic, they occupy different niches in the architectural hierarchy of autonomous agents.
The Technical Evolution of LLM Interactivity
The transition toward reliable structured data began in earnest in mid-2023. Prior to this, developers utilized third-party libraries like LangChain or Guidance to "force" models into specific formats, often through repetitive retry logic that increased both latency and API costs. The landscape shifted significantly when OpenAI introduced Function Calling in June 2023, providing a dedicated API parameter that allowed models to signal when an external tool should be invoked. This was followed by "JSON Mode" in late 2023, and eventually, the release of "Strict Structured Outputs" in August 2024, which promised 100% schema compliance.
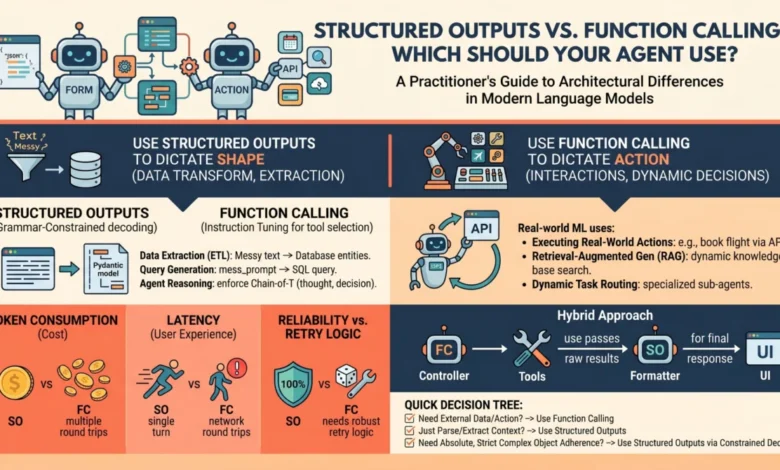
Understanding the distinction between these two methods requires an analysis of their underlying mechanics. Structured Outputs rely on a technique known as grammar-constrained decoding. In this process, the model’s output is not merely guided by a prompt but is mathematically restricted at the token-generation level. By utilizing a context-free grammar (CFG) or a JSON schema, the system masks the probabilities of any tokens that would violate the defined structure. If a schema requires a boolean value, the probability of every token except "true" or "false" is effectively set to zero. This ensures that the model cannot produce a malformed response, making it the gold standard for data extraction and transformation tasks.
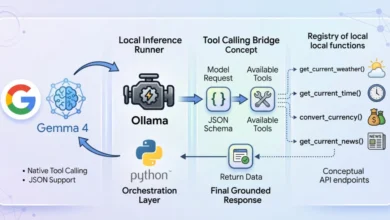
Function Calling, by contrast, is an orchestration mechanism designed for agentic autonomy. Rather than just formatting a response, Function Calling allows the model to act as a "reasoning engine" that determines which specific external capability—such as a database query, a web search, or a calculator—is required to fulfill a user’s request. This involves a multi-turn interaction where the model generates a "tool call," the developer executes that call in their local environment, and the results are fed back to the model to generate a final summary.
A Chronology of API Development and Industry Adoption
The timeline of these features highlights the rapid maturation of the AI industry’s approach to reliability:
- Pre-2023: Era of Prompt Engineering. Developers used "Few-Shot" prompting to show the model examples of JSON, with failure rates often exceeding 10% on complex schemas.
- June 2023: OpenAI launches Function Calling for GPT-3.5 and GPT-4. This introduced the
functionsparameter, later evolving intotools. - November 2023: The introduction of "JSON Mode" provided a middle ground, ensuring the output was valid JSON but not necessarily matching a specific schema.
- Early 2024: Anthropic and Google Gemini introduced native tool-use capabilities, standardizing the "Agentic" workflow across the industry.
- August 2024: OpenAI released "Structured Outputs" with a "Strict" mode, utilizing a pre-processing step that converts JSON schemas into a formal grammar for the model to follow during inference.
This progression reflects a broader industry trend: the move away from "chatbots" and toward "agents." According to internal benchmarks from various AI labs, the move from standard prompting to constrained decoding has reduced schema-related errors from roughly 5-15% to nearly 0%, a critical threshold for enterprise-grade applications.
Architectural Decision Framework: When to Use Which
For machine learning practitioners, the choice between Structured Outputs and Function Calling is often a matter of "form versus flow."
The Case for Structured Outputs
Structured Outputs should be the primary choice when the model has all the information it needs within its context window. The goal here is "data reshaping." For instance, in a medical application where a doctor’s dictated notes need to be converted into a standardized FHIR (Fast Healthcare Interoperability Resources) JSON object, Structured Outputs provide the necessary rigidity. Because there is no need for the model to "pause" and wait for external data, this method minimizes latency. Common use cases include:
- Sentiment Analysis: Extracting scores and categories from customer reviews.
- Entity Extraction: Identifying names, dates, and locations from legal documents.
- Synthetic Data Generation: Creating large batches of formatted data for training other models.
The Case for Function Calling
Function Calling is indispensable when the model lacks information or needs to affect the real world. It is the mechanism of "action." If a user asks, "What is the current stock price of NVIDIA?", the model cannot answer from its training data alone. It must use a tool to fetch real-time data. Function Calling allows the model to define the parameters for that search. The "agentic" nature of this flow means the model can decide not to call a tool if it already has the answer, or to call multiple tools in sequence. Common use cases include:
- Dynamic Information Retrieval: Accessing internal company databases or live APIs.
- System Integration: Sending an email, updating a CRM, or triggering a cloud function.
- Complex Problem Solving: Using a Python interpreter to perform high-precision mathematics that LLMs typically struggle with.
Performance, Latency, and Cost Implications
The architectural choice has significant implications for the "unit economics" of an AI application. Structured Outputs generally involve a single API call. In contrast, Function Calling is inherently multi-turn. A single user request might trigger a tool call, which requires a second API call to process the tool’s output. This effectively doubles the input token count and increases latency by the duration of the external tool’s execution plus the second model inference.
Furthermore, there is a computational "tax" associated with complex schemas. When using OpenAI’s Structured Outputs with the strict: true setting, the first request with a new schema incurs a one-time latency penalty as the system generates the artifacts required for constrained decoding. Subsequent requests are then processed at normal speeds. Developers must weigh this initial "cold start" against the long-term benefit of 100% reliability.
Industry Reactions and Expert Analysis
The developer community has largely embraced these specialized features, though some caution remains. "The challenge with Function Calling isn’t the JSON format anymore; it’s the model’s ‘judgment’ on when to call the function," notes one lead AI engineer at a major fintech firm. "Structured Outputs solved the syntax problem, but Function Calling still faces the ‘logic’ problem—ensuring the model doesn’t call a ‘Delete Database’ tool when it should have called a ‘Query’ tool."
Industry analysts suggest that the future of LLM integration lies in "Hybrid Architectures." In these systems, Function Calling is used to navigate a complex decision tree, while Structured Outputs are used at the final step to ensure the agent’s final report or data entry is perfectly formatted for the host application’s database. This "sandwich" approach leverages the strengths of both: the flexibility of tool use and the reliability of constrained generation.
Broader Implications for the AI Ecosystem
The refinement of these two mechanisms signals a maturing ecosystem where LLMs are being treated as "software components" rather than "oracles." By enforcing strict schemas, organizations can finally integrate LLMs into legacy systems that require deterministic inputs. This reduces the need for human-in-the-loop verification for routine data tasks, potentially unlocking billions in efficiency gains across sectors like insurance, legal services, and logistics.
As models become more capable, the distinction between "reasoning" and "formatting" may continue to blur. However, for the foreseeable future, the practitioner’s decision tree remains clear: if the task is to organize information, use Structured Outputs; if the task is to acquire or act on information, use Function Calling. Treating these as distinct tools in a developer’s kit, rather than interchangeable features, is the hallmark of sophisticated AI engineering in the modern era.
In summary, while Structured Outputs provide the reliable, foundational glue for data pipelines, Function Calling serves as the engine for autonomous action. Together, they represent the two pillars upon which the next generation of programmatic, reliable, and truly useful AI agents will be built.



{kind=link}