
The landscape of the open-weights artificial intelligence ecosystem has undergone a significant transformation following the release of the Gemma 4 model family by Google. Designed to provide frontier-level capabilities while maintaining a permissive Apache 2.0 license, this new generation of models offers machine learning practitioners and developers unprecedented control over their infrastructure and data privacy. By moving away from the "black box" nature of proprietary cloud-based APIs, Gemma 4 allows for the creation of sophisticated, locally hosted agents capable of interacting with the physical and digital world through a process known as tool calling.
The Evolution of the Gemma Ecosystem
The Gemma 4 release is not a singular model but a diverse family of architectures tailored for various computational environments. At the high end of the spectrum, the family includes the parameter-dense 31B model and a structurally complex 26B Mixture of Experts (MoE) variant, both designed for high-performance server environments. However, the most significant breakthrough for the edge computing community is the introduction of lightweight, efficiency-focused variants designed to run on consumer-grade hardware and mobile devices.
Historically, small language models (SLMs) struggled with the rigorous logic required for agentic workflows. They often failed to maintain the structural integrity needed for JSON outputs or lacked the reasoning capacity to know when to seek external information. Google has addressed these limitations by fine-tuning the Gemma 4 family specifically for native function calling and structured data generation. This optimization transforms these models from simple text predictors into active reasoning engines capable of executing complex workflows and conversing with external APIs in real-time.
Understanding the Mechanism of Tool Calling
Language models, in their native state, are closed systems. Their knowledge is frozen at the point of their last training data update. If a user asks a standard LLM for the current price of Bitcoin or the weather in Tokyo, the model must either admit ignorance or, more dangerously, hallucinate a plausible-sounding but incorrect answer. Tool calling, also referred to as function calling, is the architectural solution to this fundamental limitation.

Tool calling acts as a bridge between the model’s internal weights and external programmatic tools. When a model is "tool-enabled," it does not simply generate text; it evaluates the user’s prompt against a registry of available functions defined via JSON schema. If the model determines that a specific tool is required to answer the query, it pauses the text generation process. Instead, it produces a structured request—essentially a set of instructions—that the host application uses to trigger an external function. Once the function returns data (such as a temperature reading or a currency conversion rate), that information is fed back into the model. The model then synthesizes this new, live context to provide a grounded and accurate response to the user.
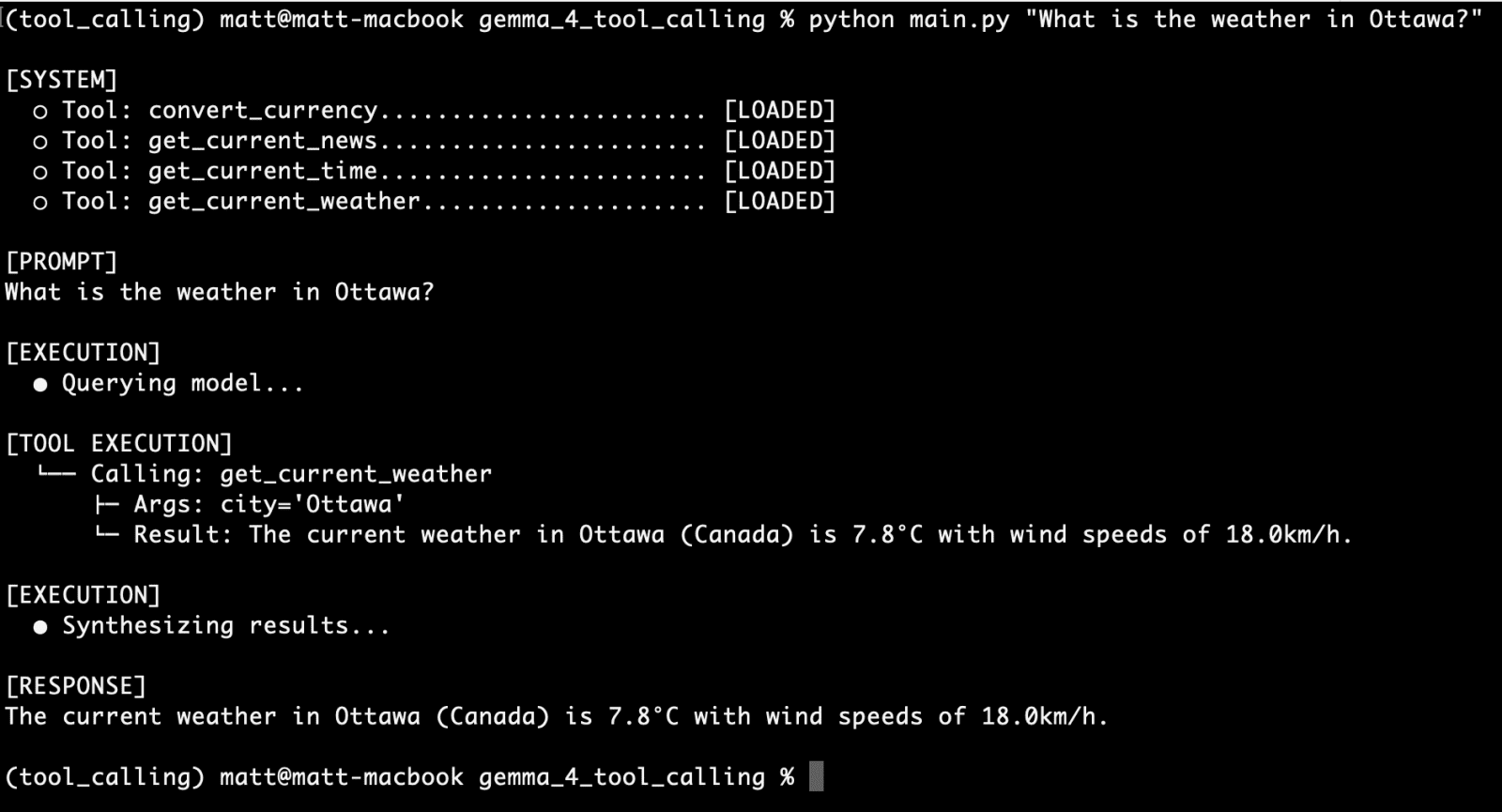
Local Inference with Ollama and Gemma 4:E2B
To achieve a truly private-first AI agent, the industry has turned toward local inference runners. Ollama has emerged as the leading platform for this purpose, providing a streamlined way to manage and run open-weights models locally. In the context of tool calling, the gemma4:e2b (Edge 2 billion parameter) model represents a paradigm shift.
Despite its small footprint, the gemma4:e2b model is engineered to inherit the multimodal properties and native function-calling capabilities of its larger 31B sibling. By activating only a portion of its parameters during inference, it achieves near-zero latency on modern laptops and even high-end mobile devices. This efficiency is critical for agentic systems where the model may need to make multiple "calls" to various tools before arriving at a final answer. Running entirely offline ensures that sensitive data—such as personal schedules, financial information, or internal company data—never leaves the local machine, while simultaneously eliminating the recurring costs and rate limits associated with commercial AI APIs.
Technical Implementation: A Zero-Dependency Approach
The implementation of a Gemma 4 tool-calling agent can be achieved using a zero-dependency philosophy in Python. By relying on standard libraries such as urllib and json, developers can ensure maximum portability and minimize the security risks associated with third-party packages.
The architectural flow of such an application follows a specific chronology:
- Tool Definition: Python functions are written to perform specific tasks, such as fetching weather data or calculating time zone differences.
- Schema Mapping: These functions are described to the model using a JSON schema that defines the function’s name, purpose, and required parameters.
- The Initial Request: The user’s query and the tool registry are sent to the Ollama API.
- The Model Decision: Gemma 4 determines if a tool is needed. If so, it returns a
tool_callsobject instead of a text response. - Execution and Re-injection: The Python script executes the requested function, captures the output, and sends the history back to the model for final synthesis.
Case Study: The get_current_weather Tool
A primary example of this capability is the integration of real-time weather data. Because weather APIs typically require specific latitude and longitude coordinates rather than city names, the tool must handle "geocoding" transparently.
A typical get_current_weather function using the Open-Meteo API involves a two-stage process. First, the function takes a city string provided by the model and geocodes it into coordinates. Second, it calls the weather forecast endpoint to retrieve the current temperature and wind speed. The model is informed of this capability through a rigid structural blueprint in JSON:
"type": "function",
"function":
"name": "get_current_weather",
"description": "Gets the current temperature for a given city.",
"parameters":
"type": "object",
"properties":
"city": "type": "string", "description": "The city name, e.g. Tokyo",
"unit": "type": "string", "enum": ["celsius", "fahrenheit"]
,
"required": ["city"]
This schema is critical because it guides the model’s weights to generate "syntax-perfect" calls. Without this level of structure, a 2B parameter model might struggle to format the arguments correctly, leading to execution errors.
Advanced Capabilities: Multi-Tool Orchestration
The true power of the Gemma 4 family is revealed when the model is asked to handle multiple tool calls simultaneously or in sequence. In testing scenarios involving complex queries—such as "I am going to Paris next week. What is the current time there, what is the weather, and how many euros is 1500 Canadian dollars?"—the model demonstrates high-level reasoning.
In this scenario, the gemma4:e2b model must:
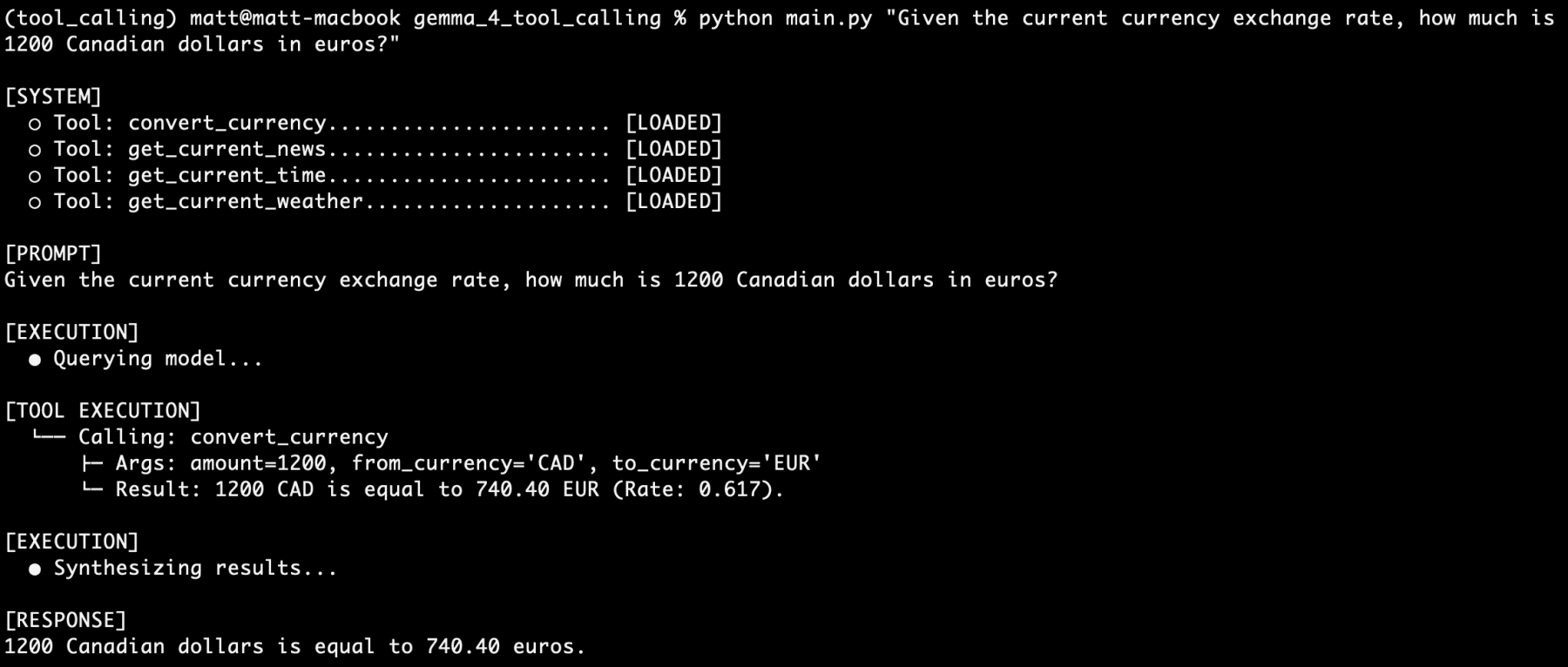
- Recognize the need for a time zone tool.
- Recognize the need for a weather tool.
- Recognize the need for a currency conversion tool.
- Identify the correct arguments for each (e.g., "Paris" for weather/time, "CAD" to "EUR" for currency).
The orchestration loop handles these calls by appending each result to the message history with the role of "tool." When the model receives the updated history, it no longer has to "guess" or "hallucinate"; it simply reads the provided telemetry data and formats it into a helpful, human-readable response.
Analysis of Implications and Industry Impact
The release of Gemma 4 and its successful implementation in local tool-calling workflows signal a move away from "agentic-as-a-service" models. For enterprises, the implications are profound. Data sovereignty is becoming a primary concern for legal and compliance departments; the ability to run an agent that can interact with internal databases and local files without exposing that data to a third-party provider is a major competitive advantage.
Furthermore, the reliability of the gemma4:e2b model in these tests—reportedly failing zero times across hundreds of prompts—suggests that the "small model gap" is closing. While 70B and 400B parameter models will always hold the edge in creative writing and deep philosophical reasoning, the "utility" tasks of the future—scheduling, data retrieval, and basic logic—are being successfully claimed by edge-tier models.
Chronology of the Local AI Shift
The transition to local tool calling has moved rapidly over the last several years:
- 2023: Early local models required massive prompt engineering and "ReAct" patterns to simulate tool use, often with high failure rates.
- 2024: The introduction of first-generation native function calling in open-weights models like Llama 3 and Gemma 2.
- 2025: Optimization of "Edge" models, allowing 2B-8B models to handle tasks previously reserved for cloud giants.
- 2026 (Current): The release of Gemma 4, providing a seamless, high-reliability framework for local agents that can operate autonomously on consumer hardware.
As developers continue to expand the "toolkit" available to these models—adding local file system access, web search capabilities, and integration with IoT devices—the distinction between a "chatbot" and a "personal AI assistant" will continue to blur. Gemma 4 stands as a testament to the viability of the open-source path, proving that privacy and power are no longer mutually exclusive in the world of artificial intelligence.






{kind=link}