The Architecture of Generative AI: Navigating the Complex Landscape of Large Language Model Engineering and Implementation
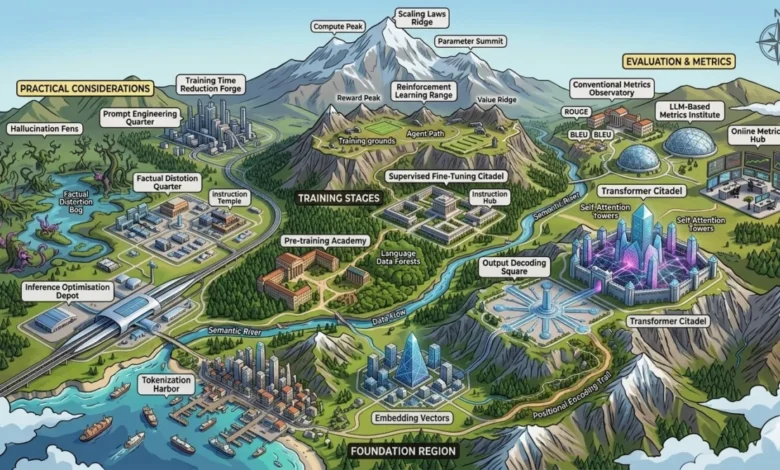
The rapid ascent of Large Language Models (LLMs) has fundamentally restructured the technological landscape, shifting the focus of software engineering from deterministic programming to probabilistic system design. As these models become the bedrock for everything from enterprise search to autonomous coding assistants, the transition for engineers entering the space has revealed a significant gap between theoretical machine learning and practical system implementation. Understanding the lifecycle of an LLM requires a holistic view of a multi-staged pipeline that begins with raw text and ends with high-performance, aligned, and optimized inference systems.

The Foundation of Digital Language: From Tokens to Meaning
At the most granular level, LLMs do not process language as humans do; they operate entirely on numerical representations. The journey from a string of text to a machine-readable vector involves three critical stages: tokenization, embedding, and positional encoding.
Tokenization serves as the first bridge. Rather than assigning a unique ID to every word—which would result in an unmanageably large vocabulary—or every character—which would strip the model of semantic context—modern systems utilize subword units. Algorithms such as Byte-Pair-Encoding (BPE) have become the industry standard, utilized by models ranging from GPT-2 to Llama 3. BPE functions by iteratively merging the most frequent character pairs into new tokens, allowing the model to handle rare words as combinations of known subwords while maintaining a compact vocabulary of roughly 50,000 to 128,000 tokens.

Once tokenized, these IDs are passed into an embedding layer. This process maps discrete integers into a high-dimensional continuous vector space. In this mathematical environment, semantic relationships are represented by geometric proximity. For instance, the vector for "queen" minus "woman" plus "man" yields a vector remarkably close to "king." However, because the standard Transformer architecture processes all tokens in a sequence simultaneously (parallelization), it lacks an inherent sense of word order. To resolve this, engineers inject positional encodings—mathematical signals that inform the model of a token’s specific location within a sentence. Approaches have evolved from the fixed sinusoidal functions used in the original 2017 Transformer paper to modern techniques like Rotary Positional Embeddings (RoPE), which better handle varying sequence lengths.
The Transformer Revolution and the Attention Mechanism
The current state-of-the-art for LLMs is the Transformer architecture, a design that superseded Recurrent Neural Networks (RNNs) by allowing for massive parallelization during training. The heart of the Transformer is the Multi-Head Attention mechanism. In this framework, every token is projected into three distinct vectors: a Query (what the token is looking for), a Key (what the token offers), and a Value (the information it contains).

By calculating the dot product of Queries and Keys, the model determines how much "attention" to pay to every other token in the sequence. This allows the model to capture long-range dependencies, such as identifying that a pronoun on page ten of a document refers to a noun on page one. However, this power comes with a significant computational cost. Standard self-attention has a quadratic complexity, $O(n^2)$, meaning that doubling the input length quadruples the memory and processing requirements. This "context window bottleneck" remains a primary area of research, leading to the development of innovations like FlashAttention and sparse attention mechanisms to handle increasingly large datasets.
A Chronology of Model Evolution
The development of LLMs has followed a rapid timeline of increasing complexity and scale:

- 2017: Google researchers publish "Attention Is All You Need," introducing the Transformer.
- 2018: BERT (Bidirectional Encoder Representations from Transformers) sets new benchmarks for natural language understanding, while GPT-1 demonstrates the power of generative pre-training.
- 2019-2020: The release of GPT-2 and GPT-3 marks the shift toward "few-shot learning," where models perform tasks without specific fine-tuning.
- 2022: The "Chinchilla" paper by DeepMind introduces scaling laws, suggesting that many models were actually under-trained relative to their size, shifting the industry focus toward data quality.
- 2023-2024: The emergence of Llama (Meta), Mistral, and Claude (Anthropic) introduces high-performance models with varied architectures, including Mixture-of-Experts (MoE).
The Multi-Stage Training Lifecycle
Training a modern LLM is an iterative process that moves from general capability to specific alignment.
- Pre-training: This is the most resource-intensive phase. Models are exposed to trillions of tokens from the open web, books, and code. The objective is "next-token prediction." During this phase, the model learns grammar, world facts, and reasoning patterns. Industry data suggests that pre-training a frontier model can cost tens of millions of dollars in compute time alone.
- Supervised Fine-Tuning (SFT): Once a base model is trained, it is "refined" on a smaller, high-quality dataset of instructions and answers. This teaches the model how to follow prompts and adopt a specific persona (e.g., a helpful assistant).
- Alignment through RLHF and DPO: To ensure safety and utility, models undergo Reinforcement Learning from Human Feedback (RLHF). Human evaluators rank model responses, and a reward model is trained to predict these preferences. Techniques like Proximal Policy Optimization (PPO) or the more recent Direct Preference Optimization (DPO) are then used to steer the model toward safer, more accurate outputs.
Addressing the Hallucination Challenge
Despite their fluency, LLMs are probabilistic engines, not databases. They are prone to "hallucinations"—generating factually incorrect but confident-sounding text. This occurs because the cross-entropy loss function used in training rewards linguistic likelihood rather than factual truth.

To combat this, engineers have turned to Retrieval-Augmented Generation (RAG). Instead of relying solely on the model’s internal weights, a RAG system queries an external vector database for relevant documents at inference time. These documents are provided to the LLM as context, grounding the response in verifiable data. Industry experts argue that for enterprise applications where accuracy is non-negotiable, RAG is no longer optional but a core requirement of the architecture.
Optimization: Training and Inference at Scale
As models grow to hundreds of billions of parameters, they no longer fit on a single GPU. Engineering these systems requires sophisticated distributed computing strategies. During training, techniques like Data Parallelism (splitting the data across GPUs) and Model Parallelism (splitting the model layers across GPUs) are essential. The ZeRO (Zero Redundancy Optimizer) stages further reduce memory overhead by partitioning optimizer states and gradients.

Inference optimization is equally critical for commercial viability. Users demand low latency (tokens per second). Key strategies include:
- KV Caching: Storing previously computed Key and Value vectors to avoid redundant calculations during generation.
- Quantization: Reducing the precision of model weights from 16-bit floating point (FP16) to 8-bit or even 4-bit integers (INT4), which drastically reduces memory usage with minimal loss in accuracy.
- Speculative Decoding: Using a smaller, faster "draft" model to predict tokens and having the larger model verify them in batches.
Evaluation: Beyond Simple Metrics
Traditional metrics like BLEU or ROUGE, which measure word overlap, have proven insufficient for evaluating the nuance of modern AI. The industry has shifted toward "LLM-as-a-Judge" frameworks. In this setup, a superior model (like GPT-4) is given a rubric to grade the responses of a smaller model. While efficient, this introduces "self-preference bias," where models tend to favor outputs that mimic their own stylistic patterns. Professional evaluation now requires a "layered" approach: unit tests for factual accuracy, automated benchmarks (like MMLU or GSM8K), and continuous human-in-the-loop monitoring to detect "behavior drift" as user queries evolve.

Broader Impact and Industrial Implications
The shift toward LLM-centric engineering has profound implications for the global economy and the labor market. Analysts from Goldman Sachs and McKinsey suggest that generative AI could add trillions of dollars to global GDP by automating routine cognitive tasks. However, the "information average" criticism remains: because LLMs minimize the distance between predicted probabilities, they often produce safe, generic content. The challenge for the next generation of engineers is to move beyond these statistical averages to create systems capable of sharp symbolic reasoning and genuine innovation.
As the field moves toward longer context windows and agentic workflows—where LLMs can use tools and execute code—the role of the engineer is evolving from a coder to an orchestrator of intelligence. Success in this new era requires a deep understanding of the entire stack, from the mathematics of attention to the cold realities of GPU memory management. The transition from "using" a model to "engineering" a system is the defining threshold of modern artificial intelligence.





{kind=link}