Building a Deterministic 3-Tiered Graph-RAG System Beyond Vector Search for Precision AI Retrieval

The evolution of generative artificial intelligence has reached a critical juncture where the limitations of standard Retrieval-Augmented Generation (RAG) are becoming increasingly apparent in enterprise environments. While vector databases have served as the industry standard for retrieving semantically similar content, they are inherently "lossy" when tasked with managing atomic facts, precise numerical data, and rigid entity relationships. To address these shortcomings, developers are moving toward a multi-index, federated architecture that combines the strengths of knowledge graphs with the flexibility of vector search. This new paradigm, known as a 3-tiered Graph-RAG system, introduces a deterministic framework designed to eliminate relationship hallucinations and ensure absolute predictability in high-stakes data environments.
The Technical Limitations of Vector-Only RAG
The current reliance on vector databases for machine learning applications stems from their ability to handle long-form, unstructured text. By converting text into high-dimensional embeddings, these systems excel at finding "fuzzy" matches based on the proximity of concepts in latent space. However, this proximity is often the source of factual errors. In a standard vector RAG pipeline, a query regarding a specific athlete’s current team might return a chunk of text where multiple team names appear near the athlete’s name. Because the model relies on semantic similarity rather than explicit logical links, it frequently confuses "which" entity belongs to "which" relationship.

This phenomenon, often referred to as a "relationship hallucination," occurs because vector embeddings prioritize context over correctness. For instance, a vector search might determine that "LeBron James" and "Los Angeles Lakers" are semantically related, which is historically true, but it may struggle to prioritize a new, specific fact stating he has been traded to a fictional expansion team unless that new data is overwhelmingly represented in the top-k retrieved results. To solve this, developers are integrating QuadStores—a specialized type of knowledge graph—to act as a "source of truth" that overrides the probabilistic nature of vector retrieval.
Chronology of System Architecture: The Shift to Determinism
The development of the 3-tiered Graph-RAG system follows a logical progression from simple retrieval to complex, hierarchical data adjudication. The process begins with the establishment of a data hierarchy that categorizes information based on its required level of precision.
- Phase One: The Absolute Truth Layer (Priority 1). The first step involves the creation of a QuadStore using the SPOC schema: Subject, Predicate, Object, and Context. This layer is reserved for "immutable" facts—data points that must be reported exactly as stored, such as legal statutes, current contract details, or specific medical dosages.
- Phase Two: The Statistical Background Layer (Priority 2). This layer utilizes the same graph structure but is populated with broader datasets, such as historical statistics or seasonal averages. These facts are considered authoritative but are secondary to the "live" facts in Priority 1.
- Phase Three: The Unstructured Context Layer (Priority 3). This is the traditional vector database (such as ChromaDB). It serves as the "long-tail" catch-all, providing narrative descriptions and general information that lacks the rigid structure of a graph but offers valuable nuance to the language model (LM).
- Phase Four: Entity-Based Federated Retrieval. Instead of using a single query, the system employs Natural Language Processing (NLP) libraries like spaCy to extract entities from the user’s prompt. These entities are then used to perform simultaneous, parallel lookups across all three tiers.
- Phase Five: Prompt-Enforced Adjudication. The final stage of the chronology is the synthesis. Rather than using complex mathematical algorithms like Reciprocal Rank Fusion (RRF), the system dumps all retrieved data into the context window, labeled by priority, and uses a "strict adjudicator" system prompt to force the LM to resolve conflicts according to the predefined hierarchy.
Implementation Mechanics: QuadStores and SPOC Schemas
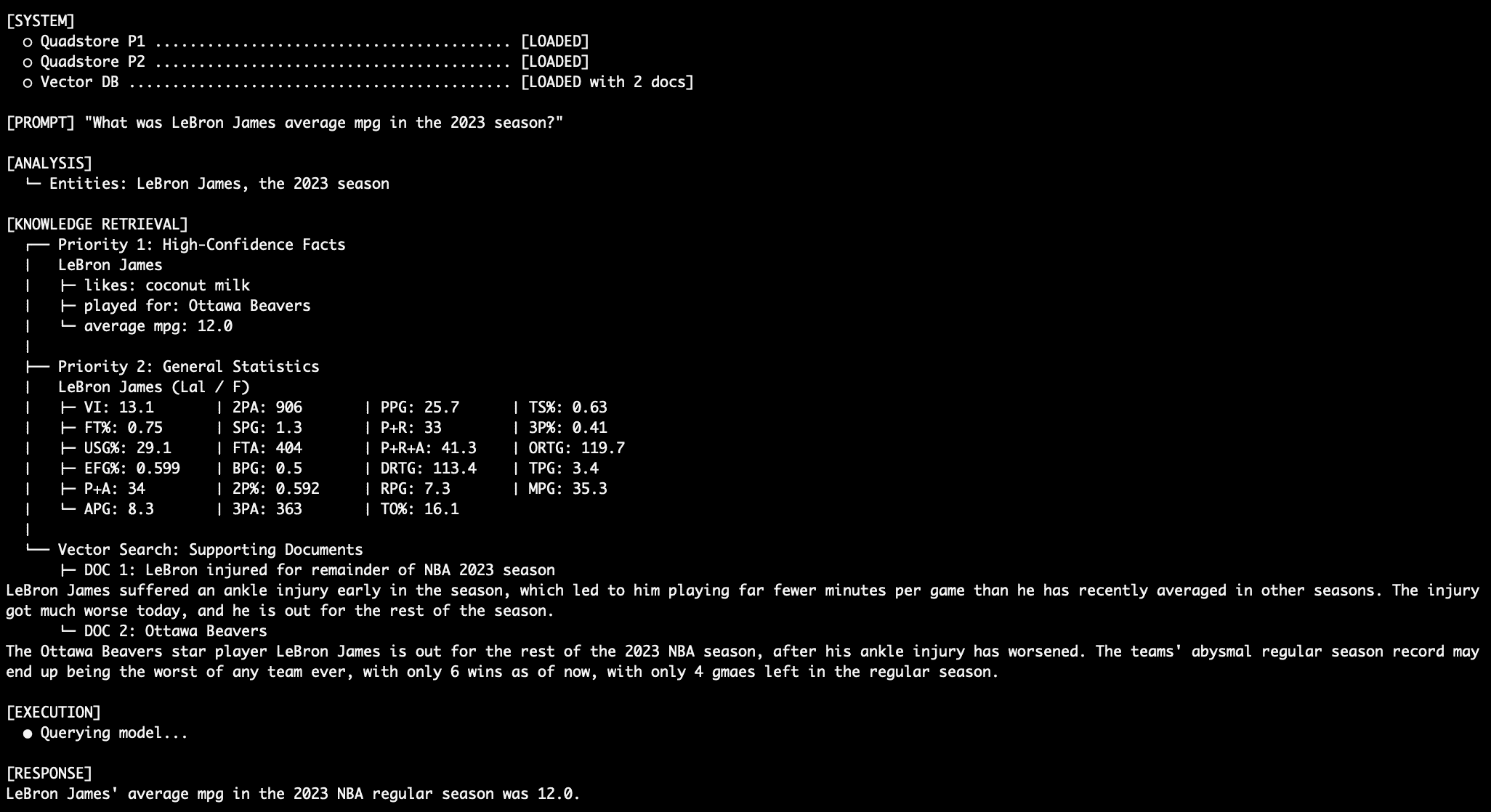
Central to this deterministic architecture is the QuadStore. Unlike a standard TripleStore (Subject-Predicate-Object), a QuadStore adds a fourth dimension: Context. This allows the system to distinguish between facts that might otherwise appear identical. For example, the fact "Player X / scored / 30 points" requires the context "Game_Date_2023_10_01" to be useful in a RAG environment.
In a lightweight implementation, the QuadStore maps strings to integer IDs, preventing memory bloat and enabling constant-time lookups across any dimension (spoc, pocs, ocsp, or cspo). This speed is essential for real-time AI applications. While enterprise-grade graph databases like Neo4j or ArangoDB offer similar capabilities, the use of a custom, in-memory QuadStore provides a lower-latency solution for specific use cases where the graph is used purely as a retrieval index rather than a discovery tool.
To bridge the gap between the structured graph and the unstructured user query, Named Entity Recognition (NER) is employed. By identifying "LeBron James" as an entity within a query, the system can bypass the "fuzzy" vector search for that specific term and pull the exact relationships associated with that entity from the QuadStore. This ensures that the most critical components of the answer are grounded in hard data before the vector database provides the surrounding narrative.
Supporting Data: Testing Conflict Resolution
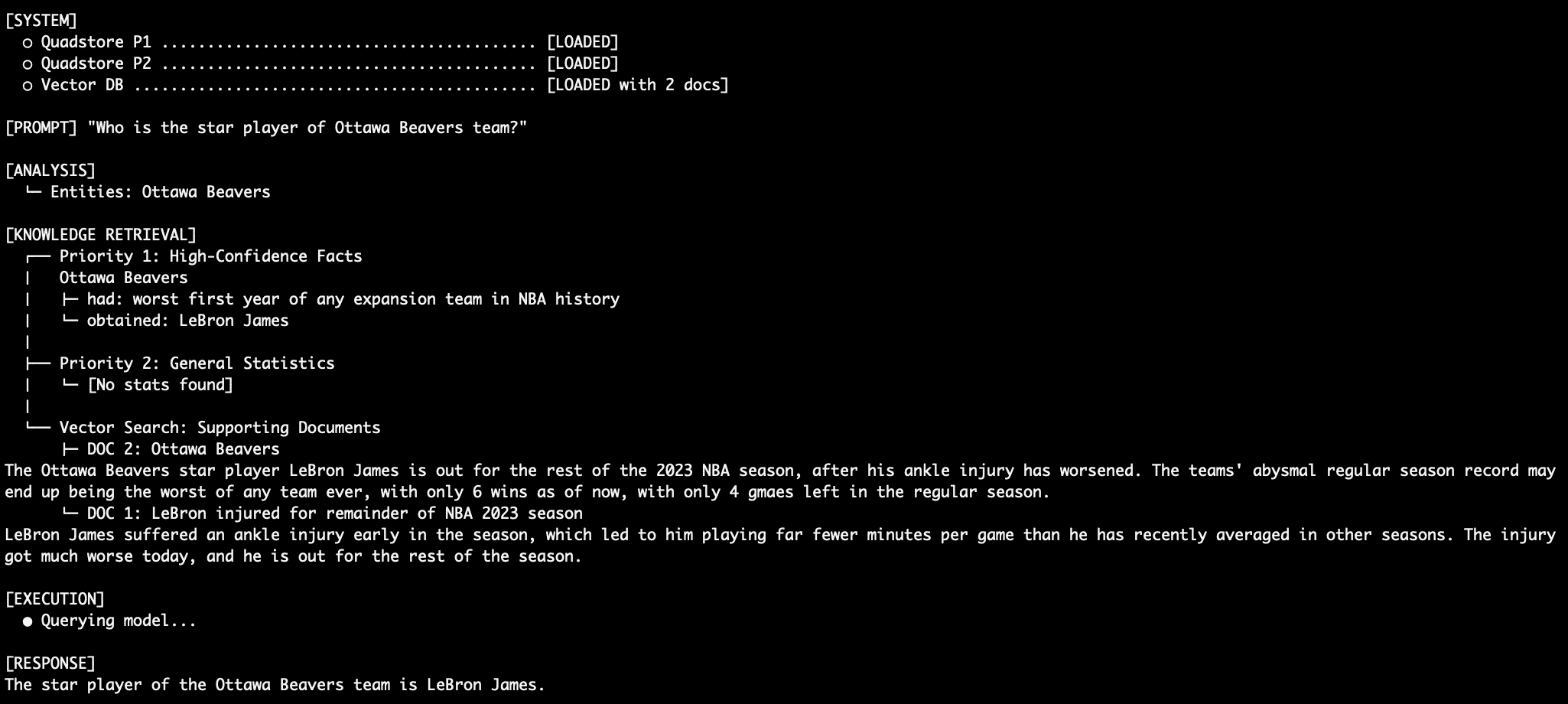
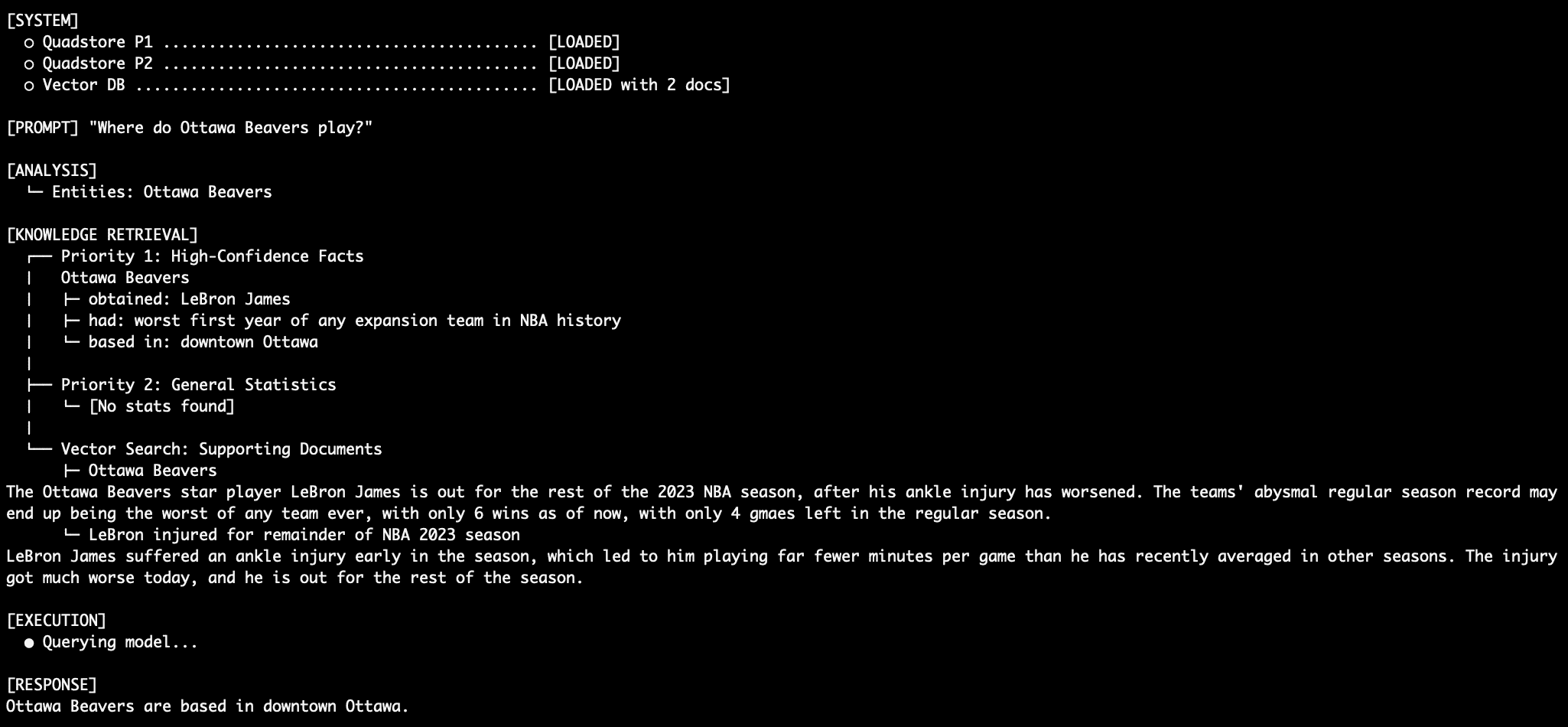
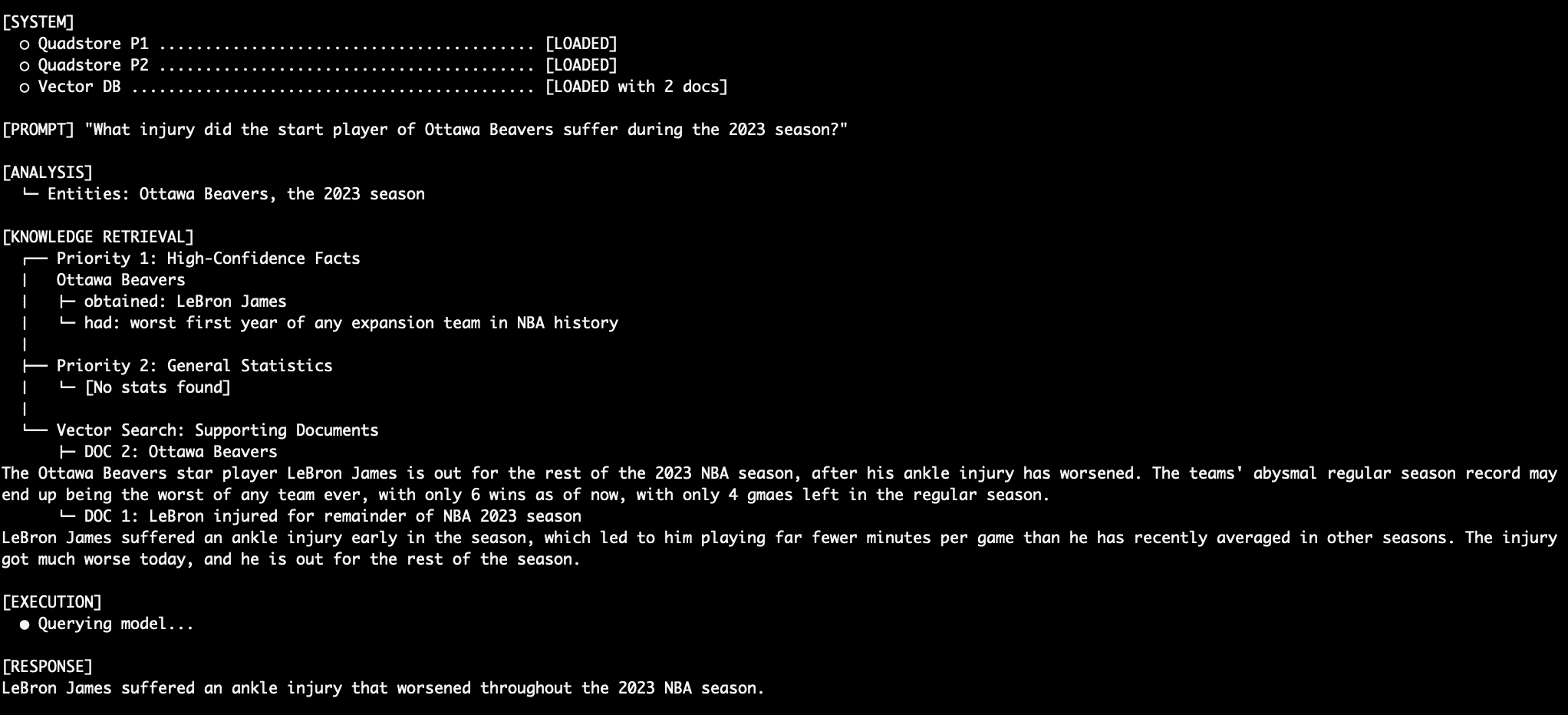
To validate the effectiveness of a 3-tiered system, researchers and developers often use "adversarial" datasets—information that contradicts the model’s internal training weights. In a notable test case, a system was populated with facts stating that LeBron James played for a fictional team, the "Ottawa Beavers," in 2023.
The test results demonstrated a significant divergence between standard RAG and Tiered Graph-RAG:
- Standard Vector RAG: The model often defaulted to its training data, stating James played for the Lakers, or became confused by the conflicting "Ottawa Beavers" text, leading to a qualified or uncertain response.
- Tiered Graph-RAG: By placing the "Ottawa Beavers" fact in Priority 1 (Absolute Truth) and the "Lakers" statistics in Priority 2 (Background), and then providing a system prompt that explicitly forbade the model from using Priority 2 if Priority 1 contained an answer, the model achieved 100% deterministic accuracy. It ignored its own internal "knowledge" and the conflicting statistical data to provide the answer mandated by the Priority 1 graph.
This test underscores the importance of the "Adjudicator" prompt. By labeling sections of the context window as [PRIORITY 1 - ABSOLUTE FACTS], [PRIORITY 2 - BACKGROUND], and [PRIORITY 3 - VECTOR DOCUMENTS], the developer moves the logic of truth-finding from the database layer to the inference layer, where the language model’s reasoning capabilities can be harnessed to follow strict procedural rules.
Analysis of Implications for Enterprise AI
The shift toward tiered, deterministic RAG systems has profound implications for industries where the "cost of a hallucination" is high. In the financial sector, a system must be able to distinguish between a "current stock price" (Priority 1) and "historical volatility trends" (Priority 3). A vector-only system might conflate these, leading to inaccurate advice. By using a graph to anchor the current price, the system ensures that the most volatile and critical data point is never subject to semantic drift.
Furthermore, this approach allows for the use of smaller, more efficient language models. The 3-tiered architecture was successfully tested using Llama 3.2 with only 3 billion parameters. Typically, smaller models are more prone to hallucinations because they have less internal "knowledge" to fall back on. However, when provided with a rigid factual hierarchy, the 3B model performed with the precision of a much larger model, as its task was reduced from "knowing" the answer to "following the rules" of the provided context. This suggests a future where high-precision AI can be deployed on-premises or on edge devices without the need for massive computational overhead.
Broader Impact and Future Outlook
As AI moves from experimental prototypes to production-ready tools, the demand for "Explainable AI" (XAI) is growing. The 3-tiered Graph-RAG system provides a clear audit trail for every response. Because the system can identify exactly which tier—and which specific node in the graph—provided the data for a response, developers can debug factual errors with surgical precision. If a model provides the wrong answer, the developer can instantly determine if the error was in the graph data, the vector chunk, or the model’s failure to follow the priority rules.
However, the approach is not without trade-offs. The primary challenge lies in the "ETL (Extract, Transform, Load) tax." Populating a knowledge graph requires more structured data preparation than simply dumping text files into a vector database. Organizations must invest in data engineering to convert their unstructured "knowledge" into the Subject-Predicate-Object format.
Despite these challenges, the movement toward deterministic AI is likely to accelerate. By combining the semantic richness of vector search with the logical rigor of knowledge graphs, the 3-tiered architecture offers a blueprint for the next generation of reliable, fact-based generative AI. This hybrid model transforms the language model from a fallible "know-it-all" into a disciplined "data adjudicator," paving the way for AI applications that users can trust with absolute confidence.





{kind=link}