The Complete Guide to Inference Caching in Large Language Models Strategies for Optimizing Performance and Cost

As large language models (LLMs) transition from experimental novelties to the backbone of enterprise-grade applications, the twin challenges of high operational costs and significant latency have moved to the forefront of engineering concerns. Inference caching has emerged as the primary architectural solution to these problems, offering a tiered approach to reducing the computational burden of generative AI. By storing and reusing the results of expensive computations, developers can bypass redundant processing, leading to substantial reductions in both Time to First Token (TTFT) and overall token expenditures. This guide examines the mechanics, economic implications, and strategic implementation of the three primary layers of inference caching: Key-Value (KV) caching, prefix caching, and semantic caching.
The Evolution of Inference Optimization: A Brief Chronology
The necessity for inference caching is rooted in the fundamental architecture of the Transformer model, first introduced in 2017. However, the practical application of caching has evolved rapidly over the last several years as models grew in size and deployment scale.
In the early period of LLM development (2017–2021), research focused primarily on model architecture and training efficiency. KV caching became a standard feature in early inference engines to handle the autoregressive nature of token generation within a single request. By 2022, as models like GPT-3 reached 175 billion parameters, the "memory wall" became a critical bottleneck, making KV caching indispensable for maintaining acceptable generation speeds.
The year 2023 marked the rise of Retrieval-Augmented Generation (RAG) and complex agentic workflows, which introduced massive system prompts and long-context windows. This created a new problem: the redundant reprocessing of identical context across different user sessions. In response, 2024 became the "Year of Context Caching," with major API providers such as Anthropic, OpenAI, and Google Gemini launching dedicated caching features. These updates allowed developers to store frequently used context on the provider’s side, fundamentally changing the cost structure of high-volume LLM applications.
The Technical Foundation: Key-Value (KV) Caching
To understand advanced caching strategies, one must first grasp the mechanism of KV caching, which operates at the lowest level of the inference stack. Modern LLMs utilize the self-attention mechanism to understand the relationship between tokens in a sequence. For every token processed, the model generates three distinct vectors: Query (Q), Key (K), and Value (V).
The attention score is derived by comparing the Query vector of a current token against the Key vectors of all preceding tokens. Because LLMs generate text one token at a time—a process known as autoregressive generation—the model must theoretically look back at the entire history of the conversation to generate the next word. Without KV caching, generating the 1,000th token would require the model to recompute the K and V vectors for the previous 999 tokens from scratch.
KV caching solves this by storing the K and V vectors in the GPU’s high-bandwidth memory (HBM) after they are computed for the first time. For each subsequent token generated, the model simply retrieves these stored values. This transforms a computational complexity that would otherwise grow quadratically into a more manageable linear progression. Today, KV caching is enabled by default in every major inference framework, including vLLM, Hugging Face Transformers, and NVIDIA TensorRT-LLM.

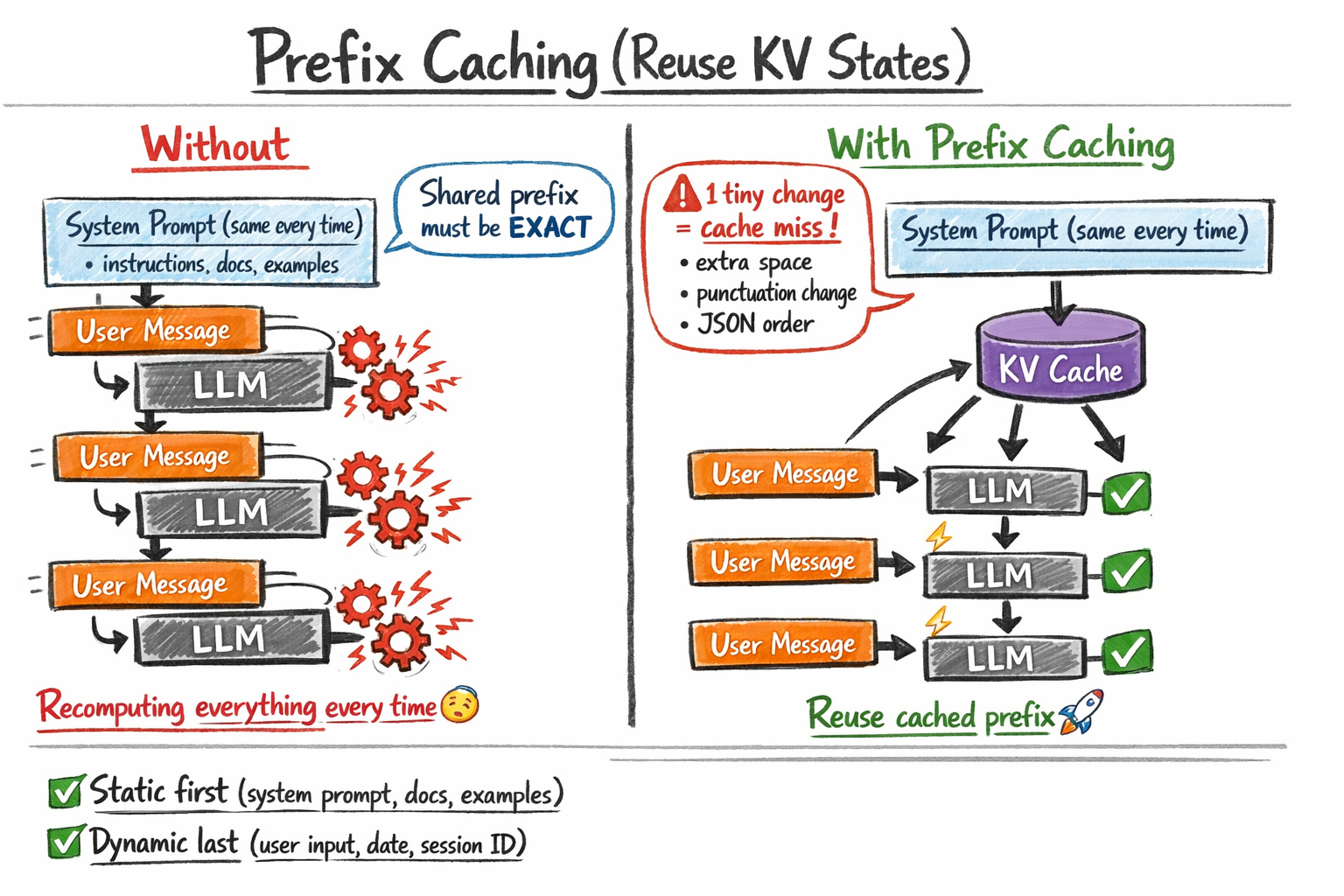
Bridging Requests with Prefix Caching
While KV caching optimizes a single session, prefix caching (often marketed as prompt or context caching) optimizes the relationship between multiple, independent requests. This strategy is particularly effective for applications that utilize a "static" system prompt followed by "dynamic" user input.
In a typical enterprise chatbot, the system prompt might include 5,000 tokens of documentation, legal disclaimers, and few-shot examples. In a traditional setup, the LLM provider recomputes the attention states for those 5,000 tokens every time a user asks a question. Prefix caching allows the inference engine to recognize that the first 5,000 tokens are identical to a previous request, allowing it to load the pre-computed KV states directly from a cache.
The implementation of prefix caching varies by provider:
- Anthropic: Developers must explicitly flag blocks of content for caching using the
cache_controlparameter. This offers a 90% discount on the cost of "read" tokens compared to "write" tokens. - OpenAI: The platform automatically caches prefixes for prompts exceeding 1,024 tokens, using a least-recently-used (LRU) eviction policy.
- DeepSeek and vLLM: These open-source-friendly options often use "Automatic Prefix Caching," which hashes blocks of tokens and automatically retrieves them if a match is found in the server’s memory.
A critical constraint of this technology is the requirement for a byte-for-byte exact match. Even a single additional space or a change in the order of few-shot examples will invalidate the cache. Consequently, engineering teams are now adopting "cache-aware" prompt engineering, where static data is strictly moved to the beginning of the prompt and dynamic variables, such as timestamps or user IDs, are placed at the very end.
Semantic Caching: Intelligence at the Edge
Semantic caching operates at the highest layer of the stack and is fundamentally different from the previous two methods. Rather than caching internal model states (KV vectors), semantic caching stores the final output of the model.
Unlike traditional web caching, which requires an exact URL or key match, semantic caching uses vector embeddings to identify queries that mean the same thing, even if they are worded differently. For example, the queries "How do I reset my password?" and "I forgot my login credentials, what is the procedure?" are semantically similar.
The workflow for semantic caching involves:
- Embedding: The user query is converted into a high-dimensional vector.
- Vector Search: A search is performed against a database (such as Pinecone, Milvus, or Redis) of previous queries.
- Similarity Thresholding: If the distance between the new query and a cached query is below a certain threshold (e.g., 0.95 cosine similarity), the cached answer is returned immediately.
This approach bypasses the LLM entirely, reducing latency from seconds to milliseconds and reducing costs to nearly zero. However, semantic caching introduces the risk of "semantic drift," where a cached answer might be slightly off-target for a nuanced new question. Therefore, it is most effectively used in high-volume environments like customer support or FAQ systems where the range of expected queries is narrow and predictable.
Economic Impact and Performance Data
The financial implications of adopting a tiered caching strategy are significant. According to data from early adopters of Anthropic’s prompt caching, enterprises running RAG pipelines with large knowledge bases have reported up to an 80% reduction in monthly API expenditures.
In terms of performance, the primary metric is Time to First Token (TTFT). For a prompt containing 10,000 tokens of context:
- No Caching: TTFT may range from 1.5 to 3 seconds as the model processes the entire prefix.
- With Prefix Caching: TTFT can drop to under 200 milliseconds, as the model only needs to process the small delta of the new user message.
Supporting data from the "vLLM" project suggests that enabling automatic prefix caching can increase the total throughput of an inference server by 2x to 4x in multi-user scenarios, as the GPU is freed from redundant computations.
Industry Reactions and Future Implications
The shift toward pervasive inference caching is fundamentally altering the AI development landscape. Industry analysts suggest that this technology is a prerequisite for the next generation of "long-context" applications, where models are expected to remember thousands of pages of documentation or hours of video.
Software engineers are reacting by moving away from "stateless" prompt design toward "stateful" architectures. "We are seeing a paradigm shift where the prompt is no longer just a string of text, but a managed asset," says one lead AI architect at a Fortune 500 firm. "The goal is to maximize cache hits. We are structuring our data pipelines to ensure that the model sees the same ‘static’ context as often as possible."
However, the rise of caching also brings new challenges in privacy and security. Semantic caches must be carefully partitioned to ensure that a response generated for one user—which might contain sensitive data—is not inadvertently served to another user with a similar query. Furthermore, "cache poisoning" has emerged as a theoretical vulnerability, where malicious users could attempt to fill the cache with low-quality or biased responses.
Conclusion: A Strategic Framework for Caching
Inference caching is no longer an optional optimization; it is a core component of the modern AI stack. For organizations looking to scale their LLM implementations, the decision framework is clear:
- KV Caching is the baseline, handled by the inference engine to ensure generation is computationally feasible.
- Prefix Caching should be the first manual optimization. It is the most effective tool for RAG and agentic workflows, providing the best balance of cost savings and accuracy.
- Semantic Caching should be layered on top for high-volume, repetitive query environments, provided the team has the infrastructure to manage a vector database and the associated embedding latency.
As the industry moves toward 2025, the integration of these caching layers will likely become more automated. We can expect inference engines to gain "intelligence" about which parts of a prompt to cache and for how long, further lowering the barrier to efficient, large-scale AI deployment. For now, the thoughtful application of these techniques remains the most effective way to turn the "expensive" promise of LLMs into a sustainable business reality.





{kind=link}