The Architecture of Agency: Beyond the Model Backbone
The central thesis of the recent research is a provocative empirical observation: the performance gap between an agent with a memory system and one without is significantly larger than the performance gap between different LLM backbones. This finding suggests that practitioners who focus exclusively on model selection or prompt engineering while treating memory as a secondary feature are misallocating resources. In the context of autonomous systems, memory serves as the "belief state" within a Partially Observable Markov Decision Process (POMDP). Because an agent cannot perceive the entire world at once, it must build and maintain an internal representation of truth to make informed downstream decisions.
In practical applications, such as research agents or simulation engines, this memory architecture allows for asynchronous collaboration and context hand-offs. For instance, in a multi-agent setup, a research agent might pass its findings to a writing agent through shared state files. Without a robust memory structure, these interactions become fragmented, leading to a loss of coherence across sessions that may span days or even weeks.
The Write-Manage-Read Loop: A New Operational Paradigm
The survey formalizes the lifecycle of agent memory into a tripartite "Write-Manage-Read" loop. While most current implementations focus heavily on the storage (write) and retrieval (read) phases, the research highlights a critical deficiency in the "manage" phase.
- The Write Phase: This involves the initial ingestion of data, observations, and interactions into the agent’s storage systems.
- The Manage Phase: This is the most complex and frequently neglected stage. It involves curation, summarization, and the hierarchical organization of information. Without active management, memory systems suffer from noise, contradictions, and bloated context.
- The Read Phase: This involves the retrieval of relevant information to inform the agent’s current task.
In high-scale distributed systems, simple file-based memory often fails to scale, necessitating the use of Vector Databases and specialized short-term/long-term memory modules. The management phase requires explicit heuristic control policies to determine what information should be stored, what should be summarized, and what should be allowed to "age out" or be discarded to maintain system integrity.
A Chronology of Memory Evolution in AI Agents
The development of memory architectures has followed a distinct chronological progression as the industry moved from simple chatbots to fully autonomous agents.
- Pre-2022: Memory was largely limited to the immediate context window of the model, resulting in "goldfish-like" behavior where agents forgot previous instructions almost immediately.
- Late 2022 – Early 2023: The rise of Retrieval-Augmented Generation (RAG) allowed agents to access static documents, but dynamic interaction history remained a challenge.
- Late 2023: The introduction of systems like MemGPT introduced the concept of an "Operating System for LLMs," treating the context window as RAM and external databases as a hard drive.
- 2024 – 2025: Emergence of reflective self-improvement frameworks (e.g., Reflexion, ExpeL) where agents conduct verbal post-mortems to store conclusions for future runs.
- 2026 (Current Frontiers): The focus has shifted toward "Policy-Learned Management," where Reinforcement Learning (RL) is used to train models to optimally invoke memory operations like "summarize" or "discard."
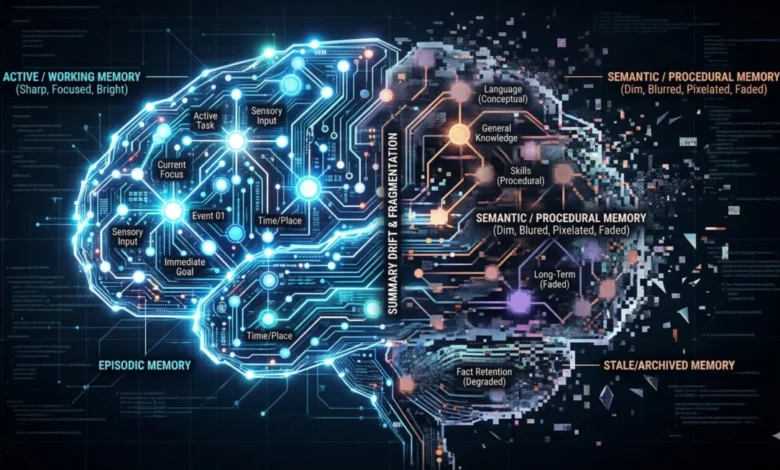
The Four Temporal Scopes of Agent Memory
The survey categorizes memory into four distinct temporal scopes, each serving a unique function in the agent’s cognitive architecture.
Working Memory
Working memory corresponds to the model’s active context window. It is high-bandwidth but ephemeral. The primary failure mode here is "attentional dilution" or the "lost in the middle" effect, where the model ignores relevant information because the context window is overcrowded. Engineers often mitigate this by creating new threads for different tasks, as keeping a single context open for too long leads to performance degradation.
Episodic Memory
Episodic memory captures specific experiences and sequences of events. In production environments, this often takes the form of daily stand-up logs or searchable timelines. This allows agents to look back at previous work, identify patterns, and avoid repeating failures. For example, an agent might remember that a specific integration failed on a previous attempt and adjust its strategy accordingly.
Semantic Memory
Semantic memory involves the distillation of facts, heuristics, and learned conclusions. Unlike episodic memory, which is a raw log of events, semantic memory is curated. It represents the "lasting truths" the agent has learned about its environment or its user. Without a rigorous curation step, semantic memory risks becoming a "junk drawer" of contradictory or irrelevant facts.
Procedural Memory
Procedural memory consists of encoded skills, behavioral patterns, and persona instructions. This is often stored in configuration files that define an agent’s "soul" or behavioral constraints. While many teams focus on prompt tuning, the research suggests that feedback mechanisms driving the storage and iteration of procedural memory are essential for long-term agent stability.
Technical Mechanisms and Retrieval Strategies
The survey identifies five primary mechanism families currently used to implement these memory scopes:
- Context-Resident Compression: Strategies like rolling summaries and sliding windows designed to keep essential information within the limited context window.
- Retrieval-Augmented Stores: The application of RAG to interaction history, allowing agents to embed past observations and retrieve them via similarity searches.
- Reflective Self-Improvement: Systems that allow agents to write their own post-mortems and store conclusions.
- Hierarchical Virtual Context: Architectures that mimic computer operating systems, managing memory through paging and archival storage.
- Policy-Learned Management: An emerging field where models are trained to manage their own memory through learned operations.
Failure Modes and Systemic Risks
As memory systems grow in complexity, they introduce new failure modes that can compromise agent reliability.
Summarization Drift and Attention Dilution
Repeatedly compressing history to fit into a context window leads to "summarization drift," where the essence of the original data is lost over time. Furthermore, even with context windows expanding to one million tokens or more, agents often fail to focus on the correct parts of the prompt, leading to generic or inaccurate outputs.
Semantic vs. Causal Mismatch
A significant limitation of current retrieval systems is the inability to distinguish between similarity and causality. Embeddings are proficient at finding text that "looks like" the query but often fail to identify the underlying cause of an issue. This leads to "thrashing," where an agent makes numerous changes without addressing the root cause of a problem.
Knowledge Integrity and Staleness
Agents often suffer from "memory blindness" or "staleness," where they continue to act on outdated information from previous years. Additionally, "self-reinforcing errors" occur when an agent treats an incorrect memory as ground truth, creating a confirmation loop that distorts its view of the world.
Broader Impact and Implications for Enterprise AI
The move toward sophisticated memory architectures has profound implications for enterprise governance and compliance. As agents begin to store more detailed information, they inevitably encounter sensitive data, including Personally Identifiable Information (PII) and Protected Health Information (PHI). This creates a tension between "faithfulness" (accurate memory) and "governance" (the requirement to delete or obfuscate sensitive data).
Furthermore, the "Utility vs. Efficiency" trade-off remains a primary concern for Solution Architects. Better memory systems require more tokens, higher latency, and more complex storage infrastructure. Enterprises must determine the point of diminishing returns where the cost of maintaining a comprehensive memory system outweighs the performance benefits.
Conclusion and Future Outlook
The findings of "Memory for Autonomous LLM Agents" suggest that the next frontier of AI development will not be defined by larger models, but by more intelligent memory management. The "Write-Manage-Read" framework provides a roadmap for builders to move beyond simple storage and toward systems that can curate, update, and protect their internal states.
For engineering teams, the practical takeaways are clear: start with explicit temporal scopes, take the management phase seriously, and treat procedural memory as a versioned asset. As autonomous systems continue to evolve, the ability to maintain a consistent, accurate, and governed belief state will be the primary differentiator between experimental scripts and production-ready intelligent agents. The path forward involves solving the currently immature areas of evaluation, governance, and policy-learned management, ensuring that agents can operate reliably in an ever-changing world.





{kind=link}